Open Data: tra la fossa della disillusione e le fondamenta della piramide
15 novembre 2019| Federico Morando
Una decina di anni fa, gli open data – o dati aperti – risalivano baldanzosamente la china del picco delle aspettative esagerate. La sommità del picco è stata probabilmente raggiunta nell’ottobre del 2013, con un report McKinsey che stimava in 3 trilioni (miliardi di miliardi!) di dollari all’anno il valore aggiunto se non “creato” almeno “abilitato” dalla pratica di mettere liberamente a disposizione i dati generati da governi e communities online.
Oggi la discussione ha sicuramente toni diversi, da fossa della disillusione per mantenere il linguaggio suggerito dal modello Hype Cycle di Gartner.
Come spesso accade, la verità sta da qualche parte nel mezzo tra le esagerazioni ottimistiche iniziali e lo scoramento che segue la consapevolezza che molte delle promesse più mirabolanti legate ad una tecnologia, concetto o movimento non potranno mai realizzarsi.
Nel linguaggio dell’Hype Cycle, è forse cominciata o comincerà presto la salita dell’illuminazione, per tornare all’altopiano della produttività… oppure dobbiamo prendere atto che dalla fossa della disillusione non si uscirà più.
Siccome personalmente penso che si stia imboccando la salita dell’illuminazione, mi ha fatto molto piacere, alcune settimane fa, essere invitato a parlare di “open data come bene comune” al Festival della Tecnologia al Politecnico di Torino. Coi miei compagni di discussione – Ciro Cattuto e Francesca De Chiara – ci siamo dati questa traccia: i dati aperti sono un bene comune che fornisce descrizioni condivise della realtà, stimola dibattiti, livella asimmetrie informative, riduce le barriere all’ingresso per startup e PMI innovative, incoraggia responsabilità e trasparenza. Governare la trasformazione digitale nell’interesse dei cittadini richiede una riflessione su meccanismi e incentivi che sostengono la creazione di tale bene comune.
In modo abbastanza naturale, la nostra discussione ha incluso una sorta di bilancio a dieci anni dall’inizio dell’hype relativo al concetto di open data. Sperando che il dibattito – con meno hype e più realismo – possa riprendere in questi anni, condivido qui qualche appunto.
Ma siccome la moda è passata da qualche anno, val la pena accertarsi di avere una definizione condivisa di Open Data. Di cosa stiamo parlando? Per definirlo in un modo compatibile con quello di molte altre persone (attivisti, ricercatori, istituzioni), mi rifaccio alla Open Definition, una serie di principi che hanno il preciso scopo di precisare il concetto di “apertura”. Secondo la Open Definition, l’aggettivo “Aperto” (Open) applicato ad un dato o contenuto “significa che chiunque può liberamente accedere, usare, modificare e condividere [il dato o contenuto] per qualunque scopo (a condizione, al più, di rispettare vincoli che preservino l’indicazione di provenienza e l’apertura stessa).” In breve: “Dati e contenuti aperti possono essere liberamente usati, modificati e condivisi da chiunque per qualunque scopo.”
Ma cosa faceva pensare a McKinsey che gli open data potessero generare 3 trilioni di dollari all’anno? O, se preferite, perché Barak Obama li ha messi al centro della Open Government Initiative? Insomma, perché ci interessa parlare di questi open data?
Riassumendo brutalmente, sono 10 anni che ci diciamo che gli open data consentono di creare conoscenza e innovazione (oggi diremmo che sono anche uno dei carburanti dell’AI e del deep learning, per agganciarci a hype più recenti). Che favoriscono la serendipità. Chi volesse approfondire, rileggendo parole scritte lungo la risalita del picco delle aspettative esagerate, può farlo ad esempio qui. Oggi, è sicuramente venuto il momento di chiederci se questi benefici degli open data siano reali.
Dunque, è tutto vero? Sì, io penso che lo sia. Non ho la pretesa di dimostrarlo in questo articolo, ma ci sono molti buoni indizi sul fatto che si possa creare conoscenza, innovazione ed anche impresa a partire dagli open data. Anzi, sta semplicemente diventando normale utilizzare, tra le tante fonti disponibili di dati e documenti, anche gli open data. Sono stato personalmente coinvolto in progetti che fanno uso dei dati aperti per creare innovazione ed impresa, ad esempio facendo business intelligence a partire dagli open data sui contratti pubblici, creando nuovi prodotti e nuova occupazione. E so per certo di soggetti, sia livello corporate che no profit, che utilizzano consulenti esterni per fare open data scouting ed integrare i dati trovati nelle loro banche dati aziendali. Insomma, c’è quantomeno una interessante “evidenza aneddotica”, come piace dire agli accademici, del valore dei dati aperti. (Più concretamente, anche se non si tratta di trilioni di dollari, posso almeno dire con certezza che gli open data pagano il mio stipendio e quello di molte persone con cui ho a che fare tutti i giorni.)
Se è vero che ci sono casi d’uso interessanti degli open data, però, è anche vero che qualcosa pare non aver funzionato, rispetto alle aspettative di 10 anni fa. Che cosa? Parlandone con un amico e socio prima del mio intervento al Festival, mi sono convinto che un modo efficace per raccontarlo sia applicare la metafora della piramide di Maslow ai dati.
Nella piramide di Maslow, i bisogni di un essere umano sono suddivisi in “gradoni” differenti, dalla base alla cima di una piramide, che parte dalle necessità più elementari (legate alla pura sopravvivenza) ed arriva sino all’autorealizzazione. Il punto è che i vari stadi devono essere soddisfatti in modo progressivo. E’ difficile occuparsi di attività sociali, se si sta morendo di fame o di freddo. E’ difficile dedicarsi all’arte o alla matematica se si è in pericolo di vita.
Ciò vale un po’ anche per i dati. Prima di generare conoscenza a partire dai dati, è necessario dedicarsi ai loro bisogni primari! E’ impossibile o fuorviante dedicarsi a belle data visualizations, se i dati non sono stati individuati, raccolti, puliti. E’ spesso inutile fare strumenti avanzati di analisi per guidare le decisioni aziendali, se non c’è una pipeline che garantisca l’aggiornamento automatico e tempestivo dei dati in input.
Cercando sul web ho poi scoperto numerose piramidi di questo tipo ed anche un bel blog post che applica questa metafora specificamente al caso dei dati usati come input per l’intelligenza artificiale.
Unendo queste suggestioni, potremmo rappresentare questa “piramide dei bisogni dei dati” più o meno così:
- Conoscenza: l’illuminazione alla cima della piramide, in cui la semantica dei dati è esplicita e si fa reasoning avanzato.
- Apprendimento e ottimizzazione: i dati permettono di fare machine learning, esercizi di ottimizzazione, in generale diventano informazioni “azionabili”.
- Arricchimento: abbiamo modo di etichettare i dati, aggregarli, creare training set, etc.
- Gestione della qualità: sappiamo misurare gli aspetti principali della qualità dei dati e gestirne la pulizia.
- Gestione dei flussi: abbiamo in piedi l’infrastruttura minima per acquisire e spostare in modo affidabile ed automatizzato i dati.
Collezione: sappiamo quali dati ci siano e dove siano.
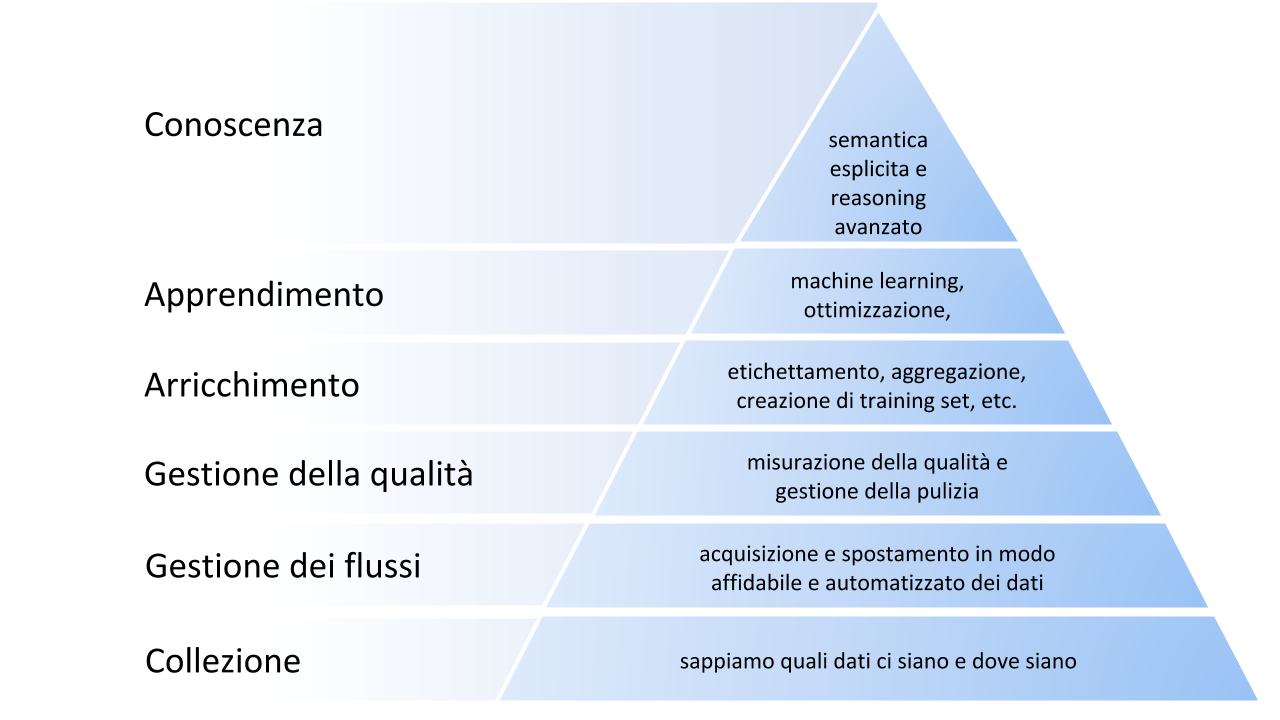
Ebbene, ad oggi, gli Open (Government) Data hanno ricevuto investimenti solo per soddisfare gli utilizzi alla base della piramide. Sono stati raccolti e perlopiù messi lì così com’erano (o, in qualche caso, introducendo errori nel processo, sporcando i dati di origine). In alcuni casi, siamo addirittura nelle fondamenta della piramide, dove anche il solo censimento dei dati a disposizione è ancora un work in progress. Siccome, però, le promesse degli open data si realizzano verso la cima della piramide, è naturale chiedersi cosa si debba fare per arrivarci.
A questo proposito, non ho ricette chiare, ma mi pare utile toccare almeno i seguenti punti.
Ci sono molti modi per andare verso la cima della piramide. Quasi tutti hanno in comune di richiedere parecchio lavoro. Nella nostra società, lavoro equivale normalmente a €, o $ se preferite. (In un’altra occasione, si potrebbe parlare anche di modelli in cui meccanismi di sharing e community generano parecchio lavoro con pochi soldi, ma si tratta di interessanti eccezioni, almeno per il momento.) Parlando di $ e piramidi, non sono riuscito a non pensare alla piramide che è rappresentata sui dollari americani. L’Occhio della Provvidenza che sta sulla cima della piramide dello stemma degli Stati Uniti d’America va un po’ oltre la “conoscenza” cui possiamo aspirare con gli Open Data, ma la metafora è appropriata. La conoscenza sta in cima alla piramide rappresentata sui dollari, e per arrivare là ci vogliono parecchi altri dollari.

Laddove non ci sia un investimento pubblico, o un benefattore, che sostiene le spese necessarie a salire lungo la piramide, uno dei modi per pagare il lavoro necessario a passare dalle fondamenta della piramide alla conoscenza che sta in cima è costruire un modello di business sostenibile sui dati stessi. Ho avuto la fortuna di essere direttamente coinvolto in progetti di questo tipo, o di fare da consulente ad aziende che lo stavano facendo. Quando la quantità e qualità di dati di base è sufficiente (es., il dato ha copertura nazionale e non solo locale; almeno una parte dei dati è ben strutturata), questo approccio può funzionare. Ad esempio, si può fare business intelligence a partire da Open Data integrati, riconciliati, ripuliti, resi più facilmente accessibili ed analizzabili, e questo mette il riutilizzatore in grado di avere le risorse per investire in dati via via migliori.
I riutilizzatori possono giustamente andare orgogliosi di migliorare la qualità degli Open Data, riuscendo anche a volte a restituire parte del valore generato a tutti i cittadini tramite servizi freemium, o magari a collaborare con associazioni no-profit e ricercatori. Resta tuttavia evidente che la maggior parte dei modelli di business richiedono che una parte dei dati e della conoscenza costruita su di essi sia accessibile soltanto agli utenti paganti. Quello per cui si paga è proprio l’accesso a questa conoscenza, e se si può averlo completamente gratis è difficile chiedere agli utenti di continuare a pagare. Anche spiegare troppo in dettaglio come passare dagli open data alla loro elaborazione è percepito come un rischio.
In conclusione, non ci avevano raccontato e non abbiamo raccontato frottole: con gli open data si può fare innovazione e creare nuova conoscenza. Tuttavia, se l’investimento per soddisfare i bisogni primari dei dati è fatto dai privati, il rischio è che i privati costruiscano modelli di business relativamente chiusi e che siano pochi quelli che decidono di farlo, perché maggiore è l’investimento necessario prima di creare nuova conoscenza tramite i dati, maggiore è il rischio di impresa da sopportare. Se invece chi pubblica i dati investe non solo nel collezionarli, ma anche nel metterli a disposizione con flussi affidabili, nel garantirne la qualità, nel descriverli ed etichettarli nel modo migliore, allora sarà più probabile che un maggior numero di soggetti privati (for profit e non) facciano i piccoli investimenti necessari a fare lo step ulteriore, che consiste nell’utilizzare questi dati di alta qualità per apprendere qualcosa di nuovo o ottimizzare processi e servizi esistenti.
eventi open data
Condividi







AZIENDE
Ecco cosa puoi fare con ContrattiPubblici.org
- analisi di mercato
- anticipare la scadenza di un contratto pubblico
- monitorare le azioni dei tuoi competitor
- trovare nuovi clienti
Scopri come
